Epidemiology
Introduction
Epidemiology is the study of the various factors influencing the occurrence, distribution, prevention, and control of disease, injury, and other health-related events in a defined human population.
Epidemiology is one of the cornerstones of public health and helps to guide policy decisions and evidence-based medicine practice by identifying risk factors for disease and targets for preventative healthcare. Epidemiologists provide input to study design, collection, analysis of data, interpretation, and dissemination of results.
Pharmacoepidemiology
Pharmacoepidemiology is the branch of epidemiology that studies the use and effect of medicines in specific population. It studies the relationships between patients, diseases, and medicines.
Some examples of applications of pharmacoepidemiology are to:
- Monitor the use and effects of medicines in populations
- Measure the occurrence of diseases
- Study the natural history of diseases
- Measure the characteristics of patients with and without specific diseases
- Identify medicine and disease associations with risks, benefits, and intended and unintended effects
- Evaluate risk minimisation measures
Some basic concepts of pharmacoepidemiology include:
- Cause-consequence
- Risk estimates
- Study types
- Data sources
- Methods
Cause-consequence
Diseases can be caused by viruses, bacteria, congenital, or acquired alterations of our metabolism due to ageing, genetic factors, and bad lifestyle habits. However, the mechanism through which an isolated factor leads to a medical condition can sometimes be very simple (skateboard fall can result in a broken arm) or sometimes very complex (taking aspirin with naproxen while being genetically susceptible and smoking and being overweight and having hypercholesterolemia and sedentarity may result in an increased risk of ischemic myocardial infarction – however, many of these factors are not absolute; for example, an individual may be a little or very overweight, and this all has an effect on the risk). With regards to health, everyone is different, and everyone might have a different, personal definition of health. Pharmacoepidemiology helps in understanding the different weight of these factors, considered as potential causes, with regards to consequences (benefit or harm).
Risk, risk rate, and relative risk
Risk (also known as cumulative incidence) has a similar meaning in epidemiology as it does in everyday usage – it is about chance. Risk is ‘the probability that a negative event will occur’. In epidemiology, risk is the observed or calculated probability that a health event will occur in a known population within a specified timeframe after exposure to a specific hazard.
For example: 200 people (the study population) go for a 2-hour walk in the snow wearing light clothes (the risk factor). After the walk, 10 people develop a cold. The risk (the number of new cases that occurred during the study) of developing a cold after walking in the snow with light clothes is therefore 5%.
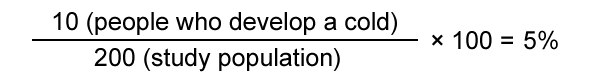
The risk rate (or incidence rate) introduces the notion of time. Risk rates also measure the frequency of new cases of a health event in a population, but they take into account the sum of time that each participant remained under observation and at risk of developing the health event under investigation. The risk rate is the frequency with which new health events occur in a particular time frame (for instance, the number of new cases in a time period). In the example above, it is 10 cases per 2 hours.
In the example, everyone walked the same amount of time (2 hours) in the snow – they were all exposed to the risk factor for the same amount of time. In real life, however, things are different. Everyone is exposed to risk factors for different amounts of time. Epidemiology provides a solution to this by considering every subject’s exposure time individually and summing it all up to build a ‘total exposure time’ for the cohort (group of people being studied).
Relative risk measures reflect the increase in frequency of the health event in one population (for instance, the exposed population) versus another population (for instance, the unexposed population), which is treated as the baseline.

Relative risk measures the strength of an association between exposure and disease. It can be used to assess whether an observed association is likely to be causal.
Types of epidemiological studies
There are different ways to carry out epidemiological studies, depending on whether the exposure is pre-determined or not (experimental and non-experimental studies), and how the assessment is done with regards to time (prospective and retrospective studies).
Experimental studies
Experimental studies determine the exposure by protocol. For instance, to study the efficacy of adding fluoride to the community water supply in preventing dental decay, two similar towns in New York State were considered. In one town, fluoride was added to the water supply; in the other town, nothing was done to the water supply. Over a period of several years, residents of both towns had dental examinations to measure the effect of the intervention.
Non-experimental studies
Non-experimental cohort studies do not determine the exposure by protocol. They are also known as observational or real-life studies. Cohort studies are often conducted with a sample of the general population (all of whom are volunteers that have given their informed consent). For example, a well-known cohort study in the USA, the ‘Nurses’ Health Study’, recruited thousands of nurses. Every two years, participants in the study are sent detailed questionnaires. The nurses report information on their diet, lifestyle, medicines, family history, work arrangements, family life, etc. They also report on any diseases they develop.
Prospective studies
Prospective studies ask a question and make an assumption between risk factor and long-term effect. Prospective trials are designed before any information is collected. Groups of similar individuals (cohorts) who differ with respect to certain risk factors are identified and followed in order to observe how these factors affect incidence rates of a certain outcome over time. For example, a prospective study might follow a cohort of middle-aged truck drivers who vary in terms of smoking habits in order to test the hypothesis that the 20-year incidence rate of lung cancer will be highest among heavy smokers, followed by moderate smokers, and then non-smokers.
Retrospective studies
Retrospective studies pose a question and look back (from observed effect to risk). They use information that has usually been collected for reasons other than research, such as administrative data and medical records. The health event being studied has already occurred (or not) by the time the trial is started. For instance, a retrospective study will select all cases of myocardial infarction from medical files and look back in time at the risk factors that could have explained this event. A case-control study is a common type of retrospective observational study in which two existing groups that differ in outcome are identified and compared on the basis of supposed risk factors.
Data used in pharmacoepidemiological research
Clinical data
Epidemiological studies can use clinical data to perform additional analyses on specific subgroups of patients included (post-hoc analysis) or combine multiple sets of clinical trials to obtain a summary of all available evidence regarding a specific treatment (meta-analysis).
Field data
Epidemiologists can collect data in the field in order to build an observational study. A very famous example is the United States National Health and Nutrition Examination Survey, which collects an exhaustive set of information about life habits, diet, and health conditions in the US.
Retrospective observational data
These are data from sources such as claims submitted to health insurance companies, electronic medical records, or medical chart reviews which are available through specific organisations. The advantage of such data is that they are usually large scale (sometimes the size of a country) and may contain a variety of information about any disease, medical procedure, treatment, and associated cost within a specific health system (for instance, an insurance company, a hospital, or an entire national health system).
Registries
Registries are prospective collections of data with a particular goal fixed in advance. For instance, there are multiple cancer registries – such as SEER (Surveillance, Epidemiology, and End Results) – and registries that follow patients treated with a particular medicine in order to monitor safety in the long term.
[glossary_exclude]Further Resources
- International Society for Pharmacoepidemiology (2007). Guidelines for good pharmacoepidemiology practices (GPP). Retrieved 14 September, 2015, from http://www.pharmacoepi.org/resources/guidelines_08027.cfm
- European Medicines Agency. (n.d.). Good pharmacovigilance practices. Retrieved from https://www.ema.europa.eu/en/human-regulatory-overview/post-authorisation/pharmacovigilance-post-authorisation/good-pharmacovigilance-practices
- European Network of Centres for Pharmacoepidemiology and Pharmacovigilance. (n.d.). Methodological Guide. ENCePP Toolkit.Retrieved 9 March, 2024, from https://encepp.europa.eu/encepp-toolkit/methodological-guide_en[/glossary_exclude]
[glossary_exclude]Attachments
- Presentation: (Pharmaco)Epidemiology
Size: 409,953 bytes, Format: .pptx
A presentation describing epidemiology, which can be adapted for own use.
A2-5.23-v1.1